
ABSTRAK
Deteksi simultan puluhan hingga ratusan metabolit dalam satu sampel timecourse metabolomik menawarkan peluang unik tetapi sering kali tidak terealisasi untuk validasi kuantifikasi. Kesesuaian timecourse individual untuk setiap metabolit pada dasarnya membingungkan kebisingan pengukuran dengan bias sampel sistematis (berasal dari, misalnya, pengenceran sampel variabel, ekstraksi, dan normalisasi). Namun, karena bias sistematis, menurut definisinya, memengaruhi semua metabolit dalam sampel dengan cara yang sama, bias tersebut dapat diidentifikasi dan dikoreksi melalui kesesuaian simultan semua metabolit yang terdeteksi dalam satu model timecourse. Studi ini menyajikan model efek campuran B-spline nonlinier sebagai formulasi praktis yang mampu memperkirakan dan mengoreksi bias tersebut. Model yang diusulkan berhasil diterapkan pada data kultur sel nyata dan divalidasi menggunakan data timecourse simulasi yang terganggu dengan berbagai tingkat kebisingan acak dan bias sistematis. Model tersebut mampu mengoreksi bias sistematis secara akurat sebesar 3%–10% hingga 0,5% rata-rata untuk data umum. Paket R untuk model koreksi telah dikembangkan untuk memfasilitasi adopsi dan penggunaan model. Formulasi efek campuran B-spline nonlinier yang diusulkan cukup umum untuk diterapkan pada berbagai bidang penelitian di luar sekadar metabolomik kultur sel.
1 Pendahuluan
Metabolomik, secara umum didefinisikan sebagai studi komprehensif molekul kecil yang dihasilkan dari metabolisme seluler, adalah teknik yang nyaman untuk mengamati hasil dari proses metabolisme kompleks sebagai fenotipe tunggal. Metabolomik telah digunakan secara luas dalam berbagai aplikasi yang berkisar dari penelitian nutrisi hingga medis. Dalam konteks medis, metabolomik sangat berharga untuk menganalisis respons seluler terhadap stresor seperti patogen, obat-obatan, dan penyakit genetik (Wanichthanarak et al. 2019 ). Dalam beberapa tahun terakhir, analisis deret waktu metabolomik (atau timecourse) semakin banyak digunakan untuk meningkatkan resolusi deteksi biomarker metabolik antara subjek dan kontrol sehat (Berk et al. 2011 ). Kombinasi pengumpulan data timecourse dengan kuantifikasi metabolit komprehensif, tipikal pengumpulan data metabolomik—menggunakan instrumen analitis seperti spektroskopi resonansi magnetik nuklir (NMR) dan spektrometri massa (MS)—menghasilkan set data yang sangat besar yang menggabungkan berbagai sumber kesalahan yang mencakup variasi individu dan teknis (Wanichthanarak et al. 2019 ). Namun, kontinuitas inheren dari sampel rangkaian waktu juga memunculkan peluang untuk pengembangan model matematika yang lebih terstruktur untuk membantu meminimalkan variabilitas dan mengkarakterisasi tren metabolisme dengan lebih baik (Montana et al. 2011 ).
Bahasa Indonesia: Dalam mempertimbangkan ketidakpastian kuantifikasi metabolomik secara keseluruhan, penting untuk membedakan antara kesalahan acak (atau gangguan), yang memengaruhi setiap metabolit dalam sampel dengan cara yang unik dan umumnya tidak dapat diprediksi, dan bias sistematis (sampel), yang memengaruhi semua metabolit dalam satu sampel (Noack dan Wiechert 2014 ). Perbedaan ini penting karena, tidak seperti gangguan acak, bias sistematis dapat dikuantifikasi dan dikoreksi. Dalam konteks metabolomik, tiga sumber paling umum dari bias yang dapat dikoreksi tersebut berasal dari variabilitas dalam pengenceran, ekstraksi, dan/atau normalisasi. Variabilitas pengenceran mengacu pada variabilitas dalam konsentrasi pelarut secara keseluruhan dan sangat umum dalam sampel biofluida seperti urin, di mana faktor-faktor seperti asupan air, diet, dan cuaca dapat memengaruhi konsentrasi yang diamati sebanyak 14 kali lipat (Wu dan Li 2016 ). Variabilitas ekstraksi berasal dari analisis metabolomik intraseluler, yang memerlukan persiapan sampel yang signifikan sebelum analisis. Kuantifikasi yang konsisten sulit dicapai karena memerlukan disrupsi sel yang lengkap, pencampuran yang sempurna dengan reagen ekstraksi, dan tidak ada degradasi metabolit (Noack dan Wiechert 2014 ). Ekstraksi yang tidak lengkap dan kebocoran metabolit dapat menyebabkan perkiraan metabolit yang terlalu rendah hingga 10 kali lipat 1 (Noack dan Wiechert 2014 ). Variabilitas normalisasi berasal dari perambatan kesalahan dari standar referensi ke sisa sampel. Misalnya, standar internal umumnya digunakan dalam kuantifikasi metabolit dalam NMR (Bharti dan Roy 2012 ) dan MS (Redestig et al. 2009 ; Lei et al. 2011 ), dengan kesalahan apa pun dalam penambahan atau kuantifikasi puncak referensi yang menyebar ke semua metabolit lainnya. Normalisasi juga digunakan untuk meminimalkan efek pengenceran. Dalam analisis urin, misalnya, konsentrasi kreatinin sering digunakan untuk memperhitungkan variabilitas dalam konsentrasi urin. Namun, karena kadar kreatinin tidak selalu mencerminkan konsentrasi urin yang sebenarnya secara akurat, perbedaan ini dapat menyebar sebagai kesalahan sistematis dalam estimasi konsentrasi semua metabolit lainnya (Wu dan Li 2016 ). Jika tidak dikoreksi, sumber bias ini tidak hanya meningkatkan ketidakpastian secara keseluruhan dan menurunkan keyakinan statistik, tetapi juga dapat menunjukkan hubungan yang salah yang mengarah pada kesimpulan yang salah.
Meskipun deteksi bias sistematis standar sederhana dalam teori, deteksi ini memerlukan jumlah replikasi sampel yang tidak praktis. Pengumpulan beberapa sampel memungkinkan kuantifikasi deviasi konsentrasi metabolit dari rata-rata keseluruhan, yang dikelompokkan berdasarkan identitas sampel. Jika, misalnya, konsentrasi semua (atau sebagian besar) metabolit 10% lebih rendah dalam satu sampel daripada yang lain, ini merupakan indikasi bias sistematis spesifik sampel. Namun, pengambilan sampel timecourse menawarkan alternatif praktis. Daripada menghitung deviasi dari rata-rata sampel keseluruhan, deviasi dapat dihitung dari tren timecourse setiap metabolit. Tren timecourse yang paling sederhana adalah spline penghalusan yang tidak membuat asumsi apa pun di luar fakta bahwa konsentrasi metabolit dianggap bervariasi dengan lancar dari waktu ke waktu, dengan apa yang disebut kecocokan “nonparametrik” yang digunakan untuk data kultur sel (Niklas et al. 2011 ) dan biofluida (Berk et al. 2011 ). Pekerjaan sebelumnya oleh Sokolenko dan Aucoin ( 2015 ) mengusulkan penggunaan deviasi relatif median dari kecocokan spline untuk mendeteksi bias sistematis; Namun, strategi koreksi yang diusulkan pada dasarnya ad hoc (pada dasarnya terdiri dari langkah-langkah penyesuaian dan pengurangan bias yang berulang). Dalam studi ini, kami menyajikan strategi pemodelan yang komprehensif untuk secara langsung mengintegrasikan estimasi bias sistematis ke dalam penyesuaian timecourse. Bias sistematis diestimasikan sebagai efek acak nonlinier yang dikombinasikan dengan regresi B-spline, yang memodelkan konsentrasi metabolit yang bervariasi dengan lancar dari waktu ke waktu untuk setiap metabolit yang diamati. B-spline adalah polinomial sepotong-sepotong yang disambung dengan lancar di knot dan dibangun sebagai kombinasi linear dari fungsi basis yang didefinisikan secara rekursif (Boor 2001 ). Model B-spline efek campuran nonlinier ini diimplementasikan menggunakan platform Bayesian Stan dan disajikan melalui paket bahasa pemrograman R yang mudah digunakan yang kami harap akan berguna bagi komunitas ilmiah yang lebih luas.
2 Metode
2.1 Perumusan Model

2.2 Kolinearitas
Estimasi unik dari
Dan
Istilah ini pada dasarnya dibatasi oleh sifat produk yang belum ditentukan
(Piazzo et al. 2019 ). Jika diambil seperti yang dirumuskan, koefisien masing-masing
bebas untuk menambah/mengurangi secara independen
, sehingga mencegah perhitungan solusi unik untuk istilah tersebut
Dan
yang membentuk produk. Fungsi B-spline dengan derajat
dan jumlah simpul
membutuhkan estimasi
parameter (Perperoglou et al. 2019 ). Dengan demikian, jika ada
titik waktu,
berfungsi sebagai batas atas perkiraan berapa banyak
istilah dapat dihitung secara unik. 2
Pemilihan yang mana
Istilah untuk memperkirakan dapat dibuat melalui proses tiga langkah. Pertama,
istilah-istilah tersebut diperkirakan dan diberi peringkat berdasarkan deviasi relatif median di seluruh metabolit pada titik waktu
, menggunakan proses yang sama seperti di Sokolenko dan Aucoin ( 2015 ). Kedua, ambang batas diterapkan untuk menentukan titik mana yang akan menerapkan istilah penskalaan, menghindari koreksi palsu pada titik-titik dengan sedikit atau tanpa bias sistematis. Ambang batas ini diperkirakan oleh model sebagai sebagian dari noise yang mendasarinya dalam set data, ditetapkan ke default 50%, yaitu, istilah bias hanya disertakan jika perkiraan awalnya melebihi 50% dari rata-rata median deviasi standar relatif yang diperkirakan dari noise pengukuran di semua tren. Ketiga, pilihan titik mana yang akan diskalakan dinilai ulang untuk memastikan bahwa matriks basis terkondisi dengan baik. Secara teknis memungkinkan untuk semua
istilah yang dipilih untuk perhitungan terjadi dalam satu kelompok sampel “di dekatnya”. Misalnya, pertimbangkan pemilihan empat sampel titik waktu pertama
untuk perhitungan dari kumpulan sepuluh sampel yang mungkin. Meskipun secara teknis terdapat derajat kebebasan yang cukup untuk menghitung B-spline unik dari enam titik yang tersisa, kualitas kecocokan ini menurun karena kurangnya nilai yang dapat diperkirakan secara unik untuk sampel satu hingga empat. Kualitas kecocokan yang tinggi dipastikan dengan menghitung nilai eigen dari matriks basis spline hanya menggunakan titik waktu yang tidak diskalakan, yaitu, sampel lima hingga sepuluh pada contoh sebelumnya. Jika nilai eigen terkecil kurang dari setengah nilai eigen terkecil yang diperkirakan menggunakan semua titik, titik tambahan dengan deviasi median terendah berikutnya dibiarkan tidak diskalakan (misalnya,
) dan proses ini diulang hingga ada cukup titik yang tidak diskalakan untuk memastikan kualitas solusi. Hal ini berdasarkan prinsip bahwa nilai eigen mendekati nol menunjukkan ketergantungan linier dalam sistem, yang membuat solusi numerik tidak stabil atau tidak akurat (Callaghan dan Chen 2008 ). Jika beberapa titik terpengaruh dalam proses ini (misalnya,
), setelah kualitas solusi dipastikan, semua kecuali titik tetap terakhir diperkenalkan kembali satu per satu untuk memeriksa apakah kriteria penerimaan masih dapat dipenuhi dengan sebanyak mungkin titik berskala. Gambaran umum yang mengilustrasikan alur kerja algoritme ditunjukkan pada (Gambar 1 ).

2.3 Implementasi
Inti dari model efek campuran nonlinier diimplementasikan menggunakan platform Stan untuk inferensi Bayesian (Tim Pengembangan Stan 2024 ), yang dibungkus dalam fungsi pemrograman R yang mudah digunakan (Tim Inti R 2014 ). Kerangka kerja Bayesian memungkinkan estimasi interval kepercayaan yang kuat. Fungsi tersebut mengambil minimal set data timecourse yang akan disesuaikan, tetapi juga memungkinkan kustomisasi parameter B-spline dan variasi ambang batas. B-spline default adalah derajat 3 dengan 1 knot, dan ambang batas default ditetapkan pada 50% dari noise dasar yang diestimasikan. Fungsi tersebut tersedia dengan versi terbaru dari paket metcourse ( https://github.com/ssokolen/metcourse ).
2.4 Validasi
2.4.1 Data yang Diamati
Data timecourse kultur sel batch diperoleh dari percobaan suplementasi media sel serangga yang dilaporkan sebelumnya (lihat Sokolenko dan Aucoin 2015 untuk detailnya). Secara singkat, sel Spodoptera frugiperda (Sf9) dikultur dari konsentrasi awal
sel/mL dalam labu kocok 125 mL pada suhu 27°C dan 130 rpm menggunakan media IPL-41 yang disuplemen khusus. Sampel supernatan kultur sel dikumpulkan setiap 24 jam selama total periode 9 hari, disentrifugasi pada 250 g selama 8 menit, dan dikuantifikasi melalui 1 H-NMR (menggunakan perangkat lunak Chenomx). Kumpulan data yang dihasilkan terdiri dari 38 metabolit yang diukur pada 10 titik waktu.
2.4.2 Data Simulasi
Data timecourse yang realistis dihasilkan menggunakan paket metcourse R (lihat Sokolenko dan Aucoin 2015 untuk detailnya). Kumpulan data simulasi tren konsentrasi senyawa ekstraseluler dihasilkan dari 20 hingga 60 tren metabolomik simulasi menggunakan kombinasi fungsi sigmoidal dan beta, diambil sampelnya menggunakan 10-20 titik waktu simulasi. Dalam setiap kumpulan data simulasi, 30% dari total tren ditetapkan meningkat, 30% ditetapkan menurun, 5% cekung, dan sisanya konstan. Derau acak dihasilkan dari distribusi normal dengan deviasi standar relatif berkisar antara 1,5% hingga 10% (sehubungan dengan rata-rata setiap tren), tergantung pada simulasinya.
2.4.3 Strategi Validasi
Koreksi bias dievaluasi melalui penambahan galat sistematis yang diketahui ke data simulasi yang dijelaskan di atas. Awalnya, galat sistematis tunggal diperkenalkan untuk memvalidasi keakuratan koreksi bias, frekuensi deteksi bias, dan selektivitas terhadap bias. Untuk ini, 200 set data deret waktu dihasilkan, masing-masing dengan 10 observasi dan 60 senyawa. Setiap set data berisi satu titik bias dengan bias 3%, 5%, atau 10% pada titik waktu yang berbeda-beda, di samping tingkat kebisingan umum pada rasio bias terhadap kebisingan 0,5, 1, atau 2, yaitu, deviasi standar relatif dari kebisingan pengukuran dihasilkan pada
Bahasa Indonesia:
, atau
bias yang dipilih. Selanjutnya, analisis diperluas untuk mencakup galat sistematis di beberapa titik untuk menilai kinerja model dalam menangani bias sistematis dan gangguan yang memengaruhi semua titik waktu. Untuk ini, 100 simulasi dibuat, dengan semua titik waktu terganggu oleh gangguan dan bias sistematis yang berasal dari distribusi normal acak dengan deviasi standar 3%, 5%, atau 10%. Selain itu, untuk menilai dampak senyawa dan pengamatan, 100 simulasi dibuat menggunakan berbagai kombinasi senyawa dan pengamatan, dengan semua titik bias dari distribusi normal dengan deviasi standar 5%. Semua kode simulasi tersedia di https://doi.org/10.5281/zenodo.13242015 .
3 Hasil
3.1 Contoh Kultur Sel
Aplikasi model yang diusulkan untuk data metabolomik kultur sel nyata disajikan dalam Gambar 2 (terbatas pada empat contoh tren metabolik yang perlu diperhatikan, meskipun hasil serupa diamati di seluruh 38 metabolit). Model tersebut mengungkapkan bahwa beberapa penyimpangan konsisten di seluruh metabolit tidak hanya disebabkan oleh gangguan acak atau pergeseran metabolik tetapi merupakan hasil dari bias sistematis. Khususnya, bias sistematis besar sebesar 4,1%, 4,1%, dan -3,1% terdeteksi dan dikoreksi pada titik waktu 5, 6, dan 7. Perbandingan antara kecocokan spline asli dan yang dikoreksi (Gambar 2A ) menunjukkan bahwa kecocokan yang dikoreksi lebih baik menggambarkan perubahan metabolik untuk tren yang meningkat dan menurun. Kecocokan awal lisin, misalnya, menunjukkan bahwa senyawa tersebut diproduksi dan kemudian dikonsumsi, skenario yang tidak mungkin untuk asam amino esensial dalam sel serangga. Namun, tren yang dikoreksi menunjukkan konsumsi berkelanjutan. Selain itu, koreksi bias sistematis diamati memiliki efek yang mendalam pada estimasi turunan pertama di seluruh titik waktu (Gambar 2B ), yang penting untuk analisis fluks metabolik yang akurat.

3.2 Kesalahan Titik Waktu Tunggal
Keakuratan dan konsistensi model yang diusulkan dalam mengoreksi bias sistematis pertama kali dievaluasi dengan memasangkan kumpulan data timecourse yang disimulasikan yang terganggu dengan satu titik bias. Penambahan satu kesalahan sistematis berguna dalam menggambarkan dengan jelas antara titik yang bias dan tidak bias dan dalam menyelidiki dampak lokasi bias pada koreksi. 200 kumpulan data, dengan 10 observasi dan 60 senyawa masing-masing, dihasilkan untuk setiap kombinasi bias (3%, 5%, atau 10%) dan rasio bias terhadap noise (0,5, 1, dan 2). Model koreksi digunakan dengan ambang batas default yang ditetapkan pada 50% dari noise acak yang diperkirakan dalam data.
Ketika mempertimbangkan bias sistematis pada titik interior, bias sistematis terdeteksi 100% dari waktu pada rasio bias terhadap derau sebesar 2% dan 70% pada rasio bias terhadap derau sebesar 1. Dengan tingkat derau yang ditetapkan menjadi dua kali bias, bias hanya dapat dideteksi 7% dari waktu. Tingkat deteksi yang rendah pada rasio bias terhadap derau yang rendah terutama dibatasi oleh pilihan ambang batas—pengurangan ambang batas dimungkinkan tetapi akan selalu meningkatkan positif palsu. Pada ambang batas saat ini, probabilitas deteksi positif palsu diperkirakan kurang dari 0,04% 2,1%, dan 7,1% dari titik waktu untuk rasio bias terhadap derau yang sesuai masing-masing sebesar 2, 1, dan 0,5. Ketika mempertimbangkan bias sistematis pada titik akhir, tidak ada bias sistematis yang dapat dideteksi pada kombinasi bias dan derau apa pun, kemungkinan karena titik akhir memiliki terlalu banyak pengaruh individual atas kecocokan spline—dengan demikian titik akhir dikecualikan dari analisis lebih lanjut.
Dalam hal akurasi koreksi, pada tingkat derau kurang dari atau sama dengan bias yang ditambahkan, model koreksi mengoreksi bias sistematis hingga dalam +/− 0,5% dari bias sebenarnya secara rata-rata (yaitu, bias sebenarnya sebesar 5% dikoreksi mulai dari 4,5% hingga 5,5% oleh model). Rata-rata, bias 3% dikoreksi sebesar 2,93%, bias 5% sebesar 4,98%, dan bias 10% sebesar 9,58%. Bias rata-rata yang dikoreksi juga ditemukan invarian di seluruh titik waktu interior. Meningkatkan tingkat derau rata-rata menjadi dua kali tingkat bias mengakibatkan penurunan akurasi model, dengan bias 3% terdeteksi rata-rata sebesar 3,94%, bias 5% sebesar 7,62%, dan bias 10% sebesar 9,53%. Tingkat derau yang lebih tinggi juga menghasilkan hasil yang lebih bervariasi, seperti yang ditunjukkan oleh rentang interkuartil (IQR) yang lebih lebar pada Gambar 3A .
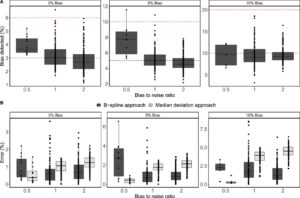
Perbandingan kesalahan–didefinisikan sebagai perbedaan absolut antara bias sistematis yang sebenarnya dan bias yang terdeteksi–dari pendekatan B-spline yang diusulkan dan pendekatan deviasi median yang diusulkan oleh Sokolenko dan Aucoin ( 2015 ) ditunjukkan pada Gambar 3B . Perbedaan kesalahan median antara kedua pendekatan dinilai menggunakan uji peringkat bertanda Wilcoxon berpasangan pada tingkat signifikansi standar 0,05. Untuk memperhitungkan beberapa perbandingan, metode Holm-Bonferroni diterapkan, dengan signifikansi statistik ditentukan pada ambang batas yang disesuaikan sebesar p ≤ 0,0056. Model yang diusulkan menunjukkan kesalahan median yang jauh lebih rendah dengan
di semua tingkat bias yang diuji saat tingkat kebisingan berada pada atau di bawah bias. Namun, pada tingkat kebisingan yang lebih tinggi sama dengan dua kali bias, pendekatan deviasi median secara signifikan lebih baik untuk bias sebesar 5% ( p = 0,002), tetapi tidak signifikan pada tingkat bias lain yang diuji. Secara keseluruhan, model tersebut mampu mendeteksi dan mengoreksi satu bias secara akurat dan tidak menambah bias tambahan dengan melakukan koreksi berlebihan, sehingga menghasilkan kecocokan yang lebih baik.
3.3 Kesalahan Beberapa Titik Waktu
Bahasa Indonesia: Setelah koreksi kesalahan titik waktu tunggal, model yang diusulkan diaplikasikan ke skenario yang lebih realistis di mana titik waktu dapat dipengaruhi oleh kombinasi kesalahan acak dan sistematis. Sebanyak 100 simulasi dihasilkan, dengan semua titik waktu terganggu oleh noise dan bias sistematis. Perlu dicatat bahwa sementara penambahan kesalahan tunggal memungkinkan diskriminasi yang jelas antara pengukuran yang “bias” dan “tidak bias”, dan dengan demikian estimasi deteksi positif palsu, tidak ada rasio positif palsu yang dapat diestimasi ketika semua titik waktu tunduk pada kesalahan sistematis. Untuk kumpulan data yang terganggu dengan kesalahan sistematis yang berasal dari distribusi normal dengan mean 0 dan deviasi standar 10%, bias yang diperkenalkan pada titik waktu berkisar dalam besaran hingga 30%. Plot bias sebenarnya versus yang diestimasikan menunjukkan bahwa sebagian besar titik yang dikoreksi terkonsentrasi dekat dengan garis 45 derajat yang mewakili koreksi sempurna (Gambar 4A ). Rata-rata, model dikoreksi hingga 6,1% dari nilai bias sebenarnya untuk bias yang besarnya berkisar dari 0% hingga 30%. Variasi dalam jumlah senyawa dan pengamatan juga dinilai dan ditemukan memiliki dampak minimal pada koreksi bias (Gambar 4B ). Dengan hanya 10 pengamatan dan 20 senyawa, bias yang berkisar hingga 15% dikoreksi rata-rata hingga 2,23% dari bias sebenarnya.

Keterbatasan model ini adalah bahwa bias sistematis dapat tidak terdeteksi dan tidak dikoreksi jika terdapat tingkat variabilitas acak dan/atau pola yang tinggi dalam distribusi bias sistematis. Misalnya, metode koreksi ditemukan gagal dalam mendeteksi bias sistematis berurutan yang memiliki tanda yang sama (Gambar 5 ). Terjadinya bias berurutan diperkirakan jarang terjadi, karena praktik pengambilan sampel yang tepat, seperti pengacakan urutan, membantu meminimalkan frekuensinya. Akibatnya, setiap estimasi tingkat kegagalan dalam deteksi kesalahan pada dasarnya bersyarat pada seberapa sering bias tersebut terjadi. Dalam kasus khusus di mana algoritme hanya menemukan tiga bias sistematis berurutan sebesar 5%, tingkat kegagalan diperkirakan sebesar 97,5%. Bias sistematis berurutan yang konsisten memiliki pengaruh yang lebih besar pada kecocokan spline, yang mengarah pada perkiraan yang lebih rendah dari deviasi relatif pada titik-titik tersebut, bahkan jika bias dasar yang sebenarnya melebihi ambang batas. Hal ini menyebabkan kegagalan dalam mendeteksi bias pada titik-titik bias dan berpotensi mendeteksi dan melakukan koreksi berlebihan untuk bias sistematis pada titik-titik yang berdekatan. Namun, pola seperti itu diperkirakan relatif jarang dan relatif mudah dikenali dengan memeriksa plot deviasi relatif.

4 Kesimpulan
Studi ini menyajikan model efek campuran nonlinier yang kuat untuk mengoreksi galat sistematis dalam data metabolomik timecourse. Model ini mengintegrasikan estimasi bias sistematis secara langsung ke dalam kecocokan timecourse, memanfaatkan struktur data deret waktu untuk membedakan antara gangguan acak dan galat sistematis. Meskipun dikembangkan dengan mempertimbangkan aplikasi pemantauan metabolomik, model ini sepenuhnya umum dan dapat diterapkan pada set data timecourse mana pun di mana galat sistematis independen memengaruhi beberapa pengamatan dalam satu sampel. Dengan parameter default, model ini dapat digunakan untuk menyesuaikan data timecourse dengan 10 titik atau lebih dan dengan sedikitnya 5–10 senyawa independen. Aplikasi pada set data kultur sel nyata dan set data simulasi dengan galat yang diketahui telah menunjukkan kemampuan model untuk secara akurat mengoreksi bias sistematis sebesar 3%-10% hingga rata-rata 0,5% untuk data umum. Mengoreksi galat sistematis dapat meningkatkan perbedaan antara tren metabolik yang disebabkan oleh gangguan biologis dan yang diakibatkan oleh galat, sehingga meningkatkan keyakinan pada hasil.



Tinggalkan Balasan