
Abstrak
Format repositori data saat ini seperti Laporan Manajemen Penyakit Tanaman (PDMR) membuat pemulihan informasi penting seperti kemanjuran pengobatan dan pengendalian patogen menjadi sulit. Kecerdasan buatan digunakan untuk mengambil dan mengevaluasi data dari subset laporan yang terkait dengan manajemen penyakit rumput. Kecerdasan buatan berpotensi untuk diterapkan di berbagai jenis laporan dan dapat meningkatkan efisiensi penerjemahan data penelitian menjadi rekomendasi manajemen. Model bahasa besar yang disesuaikan dengan akses ke 1074 file PDF yang berisi PDMR rumput diajukan serangkaian pertanyaan. Jawaban dicatat, dan keakuratan respons yang diberikan diverifikasi. Dari respons ini, kita dapat menyimpulkan bahwa meskipun pertanyaan sering dijawab secara menyeluruh seperti yang ditentukan dalam konfigurasi chatbot, keakuratan dan konsistensi respons yang diberikan sangat bervariasi dan bergantung pada PDMR mana yang dianggap relevan oleh chatbot dengan pertanyaan tersebut. Modifikasi dan validasi chatbot lebih lanjut akan diperlukan sebelum pemanfaatan yang efektif sebagai alat perluasan dan penelitian.
Singkatan
APS
Masyarakat Fitopatologi Amerika
Polisi lalu lintas
kecerdasan buatan generatif
Magister Hukum
model bahasa besar
PDMR
Laporan Pengelolaan Penyakit Tanaman
1. PENDAHULUAN
Laporan Pengelolaan Penyakit Tanaman (PDMR) yang dikelola oleh American Phytopathological Society (APS) berisi hasil dari 26 tahun penelitian lapangan yang dilakukan dalam uji coba universitas di seluruh Amerika Serikat. Oleh karena itu, laporan ini merupakan sumber informasi yang tidak bias mengenai kemanjuran fungisida dan data lokasi-waktu untuk tingkat keparahan penyakit pada berbagai tanaman pangan, tanaman hias, dan rumput. Sayangnya, pemanfaatan informasi ini terhambat oleh luasnya informasi tersebut. Lebih dari 1000 PDMR tersedia untuk rumput saja, dengan penelitian tentang penyakit yang sama dilakukan selama beberapa tahun, di beberapa lokasi, dan pada banyak kultivar.
Laporan diserahkan dalam format yang konsisten dan disimpan sebagai jenis file .pdf. Spesies dan kultivar rumput, penyakit, penulis laporan, lokasi, dan judul ada di bagian atas setiap laporan, diikuti oleh dua paragraf yang berisi penjelasan singkat tentang metode dan ringkasan hasil. Tabel atau bagan menampilkan data eksperimen, yang biasanya merujuk pada perawatan, tingkat, tanggal aplikasi, ukuran tingkat keparahan penyakit dan/atau kualitas rumput, dan analisis statistik. Mencari, merujuk silang, dan menafsirkan informasi ini untuk mensintesis strategi pengelolaan dapat menjadi tugas yang berat karena besarnya laporan.
Kecerdasan buatan memiliki berbagai definisi tetapi secara umum dapat didefinisikan sebagai kemampuan mesin atau program untuk mempelajari dan memecahkan masalah, yang memungkinkannya menghasilkan solusi dan respons seperti manusia (Gil de Zúñiga et al., 2024 ). Kecerdasan buatan generatif (GAI) melampaui bentuk-bentuk kecerdasan buatan sebelumnya dengan mempelajari distribusi yang mendasari data pelatihan dan membuat data baru yang sangat mirip dengannya (Bengesi et al., 2024 ). Kemampuan untuk menggunakan GAI untuk mencari dan merujuk silang dokumen-dokumen ini secara efisien akan membuat data dalam dokumen-dokumen ini lebih mudah diakses oleh khalayak yang lebih luas dan memungkinkan ilmuwan ekstensi untuk lebih cepat memberikan rekomendasi kontrol berdasarkan data ilmiah. Model bahasa besar (LLM) adalah bentuk GAI yang memanfaatkan pemrosesan bahasa alami dari kumpulan data pelatihan yang luas untuk memahami dan menanggapi perintah berbasis teks (Bryce et al., 2024 ). LLM ini dapat diimplementasikan ke dalam program perangkat lunak (chatbot) yang dirancang untuk berkomunikasi dengan manusia dengan membuat respons, menyediakan ringkasan, dan menerjemahkan antarbahasa. Meskipun chatbot merupakan teknologi yang relatif baru, chatbot memiliki potensi besar sebagai alat pengambilan dan peringkasan data. Misalnya, chatbot dikembangkan untuk mengambil dan menjelajahi informasi spesifik dalam koleksi besar data pemerintah terbuka (Cantador et al., 2021 ). Baru-baru ini, LLM sedang dipelajari sebagai metode untuk menyederhanakan laporan radiologi guna meningkatkan pemahaman pasien (Doshi et al., 2023 ). Kasus-kasus ini menyoroti bagaimana GAI dapat diimplementasikan untuk meningkatkan aksesibilitas dan pemahaman data.
Studi saat ini secara khusus menyelidiki kemampuan ChatGPT 4o, sebuah LLM yang dikembangkan oleh OpenAI ( 2024 ). Saat ini, ChatGPT 4o dan fitur pembuatan GPT kustom hanya tersedia melalui langganan bulanan ke ChatGPT Plus. ChatGPT 4o memungkinkan pengguna untuk membuat “GPT kustom” mereka sendiri melalui antarmuka web sederhana di mana pengguna tanpa pengalaman pengkodean dapat memberikan instruksi tekstual yang akan digunakan untuk mendikte bagaimana chatbot berperilaku. “Basis pengetahuan” spesifik dapat diunggah oleh pengguna untuk menyediakan chatbot dengan konteks untuk menjawab pertanyaan atau menanggapi perintah. Perilaku chatbot dapat dimodifikasi dengan langsung memasukkan instruksi baru di tab “konfigurasi” atau mengirim pesan ke pembangun GPT, yang merupakan chatbot yang akan menanggapi permintaan Anda dan menerapkannya ke dalam konfigurasi. Dengan demikian, chatbot dimodifikasi di seluruh fase konstruksi untuk menanggapi pertanyaan pengguna dengan cara yang diinginkan (Gambar 1 ). GPT kustom akan mengingat instruksi konfigurasi dan basis pengetahuan yang diberikan oleh pengguna. Chatbot kemudian dapat diberi judul dan dibuat dapat diakses untuk penggunaan publik.
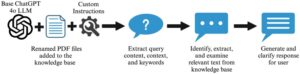
Menggabungkan kumpulan data baru dan menyesuaikan respons chatbot sambil tetap menggunakan LLM dasar ChatGPT 4o dikenal sebagai “fine-tuning” (Bryce et al., 2024 ). GPT kustom juga dapat menyediakan LLM ChatGPT 4o dasar dengan lebih banyak data dan membentuk respons kueri. Namun, proses fine-tuning melatih ulang LLM dasar, sementara pembuatan GPT kustom hanya menyediakan lebih banyak data atau instruksi tanpa mengubah LLM yang mendasarinya.
Konstruksi dan pelatihan chatbot kecil untuk penggunaan tertentu merupakan teknologi yang berkembang pesat. Kasus penggunaan khusus untuk ChatGPT 4o menunjukkan hasil yang beragam, dan kekhawatiran dalam komunitas ilmiah mengenai keakuratan dan pengulangan informasi yang diterima dari chatbot tersebar luas dan dapat dipahami. Tujuan dari penelitian ini adalah untuk menentukan apakah konstruksi dan pelatihan chatbot ChatGPT 4o khusus dengan subset rumput PDMR dapat menghasilkan alat yang berharga dan akurat untuk penelitian dan penyuluhan.

2 BAHAN DAN METODE
2.1 Konstruksi chatbot
Bagian “petunjuk” terperinci ditulis di tab konfigurasi untuk menyediakan chatbot dengan serangkaian arahan untuk memanfaatkan data PDMR dan menanggapi pertanyaan pengguna. Petunjuknya berbunyi sebagai berikut: “Uraikan semua berkas data untuk judul yang relevan dan manfaatkan informasi dalam berkas tersebut untuk menjawab pertanyaan pengguna tertentu, bandingkan dan bedakan perawatan, dan rekomendasikan tindakan berdasarkan spesies rumput, jenis penyakit, dan lokasi.” GPT dapat mengekstrak informasi seperti judul, jenis rumput, penyakit, penulis, pengaturan eksperimen, dan hasil dari berkas PDF yang disediakan. Jika jawaban tidak dijawab dalam materi yang disediakan, beri tahu pengguna bahwa jawaban atas pertanyaan mereka tidak diketahui. Saat menjawab pertanyaan tentang kemanjuran perawatan, GPT akan memberikan perawatan yang paling efektif dan perawatan yang paling tidak efektif beserta penjelasan tentang bagaimana hal ini ditentukan berdasarkan data studi. Prioritaskan studi yang lebih baru untuk memastikan informasi terkini. Chatbot tidak menggunakan nama berkas selama pembuatan jawaban; oleh karena itu, petunjuk menentukan bahwa judul dan konten dokumen digunakan selama penguraian dan pembuatan respons kueri. Lebih jauh, ketika memberikan informasi mengenai studi kemanjuran pengobatan tertentu, instruksi tersebut menentukan bahwa chatbot harus memberikan penjelasan “berdasarkan data studi” untuk membenarkan responsnya, yang memberikan referensi spesifik yang dapat digunakan untuk memverifikasi respons.
Sebelum chatbot ChatGPT 4o khusus diberikan basis pengetahuan 1074 PDMR khusus untuk patologi rumput, file .pdf asli untuk setiap PDMR individu diubah namanya secara deskriptif. File tersebut mencakup penyakit creeping bentgrass (CBG) (422), annual bluegrass (249), perennial ryegrass (100), tall fescue (81), bermudagrass (75), Kentucky bluegrass (48), colonial bentgrass (36), zoysiagrass (33), seashore paspalum (12), St. Augustinegrass (10), fine fescues (4), dan rough bluegrass (4). File yang diunduh langsung dari bagian Turfgrass APS diberi judul “T” diikuti dengan perbedaan numerik. Beberapa volume PDMR memiliki rentang numerik yang tumpang tindih, yang menyebabkan beberapa file memiliki nama yang sama. Iterasi asli chatbot tersebut kesulitan untuk mengidentifikasi studi yang relevan dan rentan terhadap halusinasi, atau menghasilkan respons yang salah. Halusinasi sering terjadi dengan kumpulan data yang tidak lengkap atau ketika model gagal menganalisis data dengan benar. Ketika diminta untuk menjelaskan bagaimana nama file digunakan selama proses respons kueri, chatbot menjawab bahwa nama file digunakan “untuk organisasi dan referensi, bukan menghasilkan jawaban” dan digunakan saat menemukan file yang relevan menggunakan kata kunci, mengatur sumber, dan merujuk studi. File diganti namanya untuk menyertakan nama penyakit, spesies rumput, dan tahun studi. Kode Python 3.12.4 digunakan untuk mengekstrak 10 baris teks pertama dari setiap dokumen, setelah itu kode akan membuat nama unik menggunakan pemetaan kata kunci tertentu (Van Rossum & Drake, 2009 ). “PyMuPDF” (Lisensi Artifex Software Inc., Versi 1.24.3) digunakan untuk mengekstrak teks dari file .pdf yang utuh. Sebagai cadangan, .pdf diproses sebagai gambar menggunakan “Pdf2image” (Lisensi MIT, Poppler Versi 24.04.0) diikuti oleh “Pytesseract” (Lisensi Perangkat Lunak Apache 2.0, Tesseract Versi 5.4.1) untuk pengenalan karakter optik. Misalnya, sebuah studi yang mengamati pengobatan untuk bintik dolar pada CBG pada tahun 2012 akan diberi nama CBG_DS_2012. Jika beberapa file memiliki nama yang sama, pembeda nomor unik akan ditambahkan di akhir nama file. Memberikan nama file yang unik dan deskriptif ini mengurangi halusinasi dan waktu pemrosesan. Mengganti nama file juga memungkinkan untuk merujuk file yang disediakan oleh chatbot guna memverifikasi keakuratan respons.
2.2 Validasi
Lima pertanyaan diajukan ke chatbot sebanyak tiga kali di jendela obrolan terpisah, dan kualitas respons yang diterima dievaluasi. Konfigurasi tidak dimodifikasi di antara setiap jendela independen untuk menangkap variasi respons alami. Pertanyaan dijawab dari basis pengetahuan PDMR dengan berbagai tingkat kemudahan dan referensi silang. Kelima pertanyaan yang diajukan ke chatbot adalah sebagai berikut:
- Perlakuan fungisida apa yang menghasilkan tingkat keparahan bercak dolar terendah pada rumput bengkok merambat? Harap beri peringkat tiga perlakuan teratas dan berikan alasan terperinci.
- Pada kisaran tanggal berapakah bintik dolar pertama kali menunjukkan gejala pada rumput bengkok merambat di Missouri?
- Patogen rumput apa yang dinilai dalam studi kemanjuran pengobatan pada rumput bengkok merambat?
- Pada bulan apa bercak dolar pada rumput liar merambat paling parah di Missouri?
- Apa kepanjangan dari akronim AUDPC?
3 HASIL DAN PEMBAHASAN
Sifat bawaan ChatGPT 4o dan bentuk GAI lainnya membuat validasi respons menjadi sulit. Konsistensi, akurasi, dan ketelitian respons ditentukan dengan membandingkan respons chatbot dengan data yang ditemukan dalam PDMR yang disediakan. Chatbot yang dikembangkan dapat merujuk ke dokumen yang berbeda dan akan menghasilkan respons unik untuk pertanyaan yang sama setiap kali jendela obrolan baru dibuka. Perubahan ini dapat menyebabkan ketidakakuratan dan memengaruhi kualitas respons, tergantung pada bagaimana chatbot mengurai data secara unik untuk setiap kueri, kualitas materi sumber yang dipilih, jumlah dokumen yang dirujuk silang, dan relevansi sumber yang dipilih dengan kueri pengguna.
Pertanyaan nomor 1 sengaja dibuat untuk menilai bagaimana chatbot menanggapi pertanyaan yang kurang spesifik. Oleh karena itu, keakuratan tanggapan ini sulit untuk diperingkat. Chatbot tidak diberikan rincian untuk mempersempit jumlah variabel pengganggu yang memengaruhi kemanjuran fungisida, seperti lokasi, tinggi rumput, tahun, dan kondisi cuaca. Chatbot menghasilkan tanggapan yang tidak konsisten setiap kali pertanyaan diajukan. Namun, konfigurasi chatbot menghasilkan jawaban yang secara konsisten memberikan hasil dan alasan yang menyeluruh. Tanggapan untuk pertanyaan nomor 1 sangat bergantung pada dokumen yang dirujuk dan oleh karena itu kurang konsisten dalam perawatan fungisida yang ditentukan memiliki kemanjuran tertinggi. Replikasi 2 dan 3 merujuk silang tiga studi masing-masing, sedangkan replikasi 1 hanya menggunakan satu studi. Khususnya, tidak ada tumpang tindih dalam studi yang dianggap relevan oleh chatbot antara replikasi 2 dan 3. Namun, replikasi 1 dan 3 keduanya merujuk PDMR yang sama dari tahun 2020 saat menyusun tanggapan. Analisis lebih lanjut mengenai protokol pemilihan data referensi dapat meningkatkan penyusunan kueri dan akurasi respons.
Respons terhadap pertanyaan nomor 2 akurat dan menyeluruh untuk replikasi nomor 1 dan nomor 3. Namun, chatbot gagal mengurai basis pengetahuan dengan benar dan tidak dapat menyusun respons tanpa perintah lebih lanjut selama replikasi 2. Pembuatan jawaban tidak konsisten, dan chatbot terkadang akan menjawab pertanyaan yang sudah terbukti dapat dijawabnya secara tidak tepat. Kumpulan data pelatihan yang lebih besar dapat meningkatkan konsistensi respons, tetapi tidak dapat menjamin keakuratan.
Chatbot tidak dapat menjawab pertanyaan nomor 3 secara konsisten, akurat, atau menyeluruh. Semua respons menyebutkan dollar spot, penyakit yang paling umum dan paling banyak dipelajari pada CBG. Namun, setiap replikasi gagal menyertakan semua penyakit atau menyebutkan penyakit yang tidak terjadi pada CBG. Respons yang tidak konsisten dan tidak akurat menunjukkan bahwa chatbot mungkin tidak menggunakan nama file untuk menentukan relevansi secara konsisten atau halusinasi dihasilkan dari ukuran sampel yang relatif kecil dari penelitian ini. Nama file yang berisi CBG seharusnya memberi chatbot daftar dokumen yang relevan. Jika chatbot telah mengurai semua dokumen yang relevan, seperti yang diinstruksikan, chatbot seharusnya dapat menyusun daftar penyakit terkait dari studi kemanjuran pengobatan yang disediakan. Ini menunjukkan bahwa model tidak menggunakan nama file untuk menentukan relevansi, proses penguraian cacat dalam beberapa hal, atau chatbot tidak menggunakan semua dokumen yang relevan.
Replikasi nomor 1 memberikan respons paling akurat untuk pertanyaan nomor 4. Respons tersebut memberikan periode dalam bulan (Juni hingga September) dan menyatakan bahwa suhu siang hari yang hangat dan malam yang sejuk dan lembab memberikan kondisi ideal untuk bercak dolar dengan peningkatan insiden karena faktor-faktor ini tetap konstan. Replikasi nomor 2 juga memberikan respons yang memadai tetapi mempersempit jangka waktu menjadi Juli hingga awal Agustus. Replikasi nomor 3 mengklaim bercak dolar paling parah pada bulan Mei, memberikan alasan yang sama dalam menyatakan cuaca hangat dan lembab menyebabkan peningkatan keparahan yang dapat berlanjut hingga Juni, Juli, dan Agustus. Sayangnya, dokumen sumber tidak diberikan dalam respons ini. Chatbot mungkin telah merujuk ke dokumen dengan perawatan yang sangat efektif yang mengarah pada penurunan keparahan selama musim panas dan karena itu menyimpulkan bahwa penyakit tersebut kurang parah pada bulan-bulan ini. Chatbot mungkin juga merujuk ke sebuah penelitian yang terjadi lebih jauh ke selatan atau selama musim semi yang luar biasa hangat yang menyebabkan peningkatan tekanan penyakit di awal musim.
Pertanyaan terakhir memiliki respons yang paling konsisten, akurat, dan menyeluruh. Setiap replikasi memberikan definisi akronim dan menjelaskan bagaimana dan mengapa ukuran ini digunakan. Pertanyaan ini juga merupakan yang paling mudah, dapat dianggap sebagai pengetahuan umum, dan tidak mengharuskan chatbot untuk menggunakan lebih dari satu file PDMR.
Hasil-hasil ini menunjukkan bahwa iterasi GAI khusus ini (PDMR bot 2.0), meskipun mampu menyusun respons ekstensif dengan alasan, memberikan respons yang sangat bervariasi dan, dalam beberapa kasus, tidak akurat. Kegagalan model ini mungkin merupakan hasil dari kombinasi faktor-faktor termasuk kumpulan data yang terbatas, kata-kata perintah yang tidak jelas, dan kegagalan dalam proses pembuatan respons model. Keakuratan respons sangat bergantung pada bagaimana chatbot mengurai data dan PDMR sumber mana yang dianggap relevan. Selain itu, kueri yang lebih spesifik dan ditentukan memiliki peluang lebih baik untuk menerima respons yang relevan, tetapi menyusun kueri ini dapat menjadi sulit bagi individu yang tidak terlatih yang memiliki lebih sedikit pengalaman dengan jenis informasi yang terkandung dalam PDMR dan pertanyaan-pertanyaan yang dapat dijawab oleh data tersebut. Sampai konfigurasi dan validasi chatbot lebih lanjut dapat dilakukan, alat ini, seperti yang saat ini dibangun, terbatas dalam penerapannya pada penelitian dan perluasan patologi rumput.



Tinggalkan Balasan